

Predibase Launches Next-Gen Inference Stack for Faster, Cost-Effective Small Language Model Serving
Predibase Launches Next-Gen Inference Stack for Faster, Cost-Effective Small Language Model Serving
Predibase's Inference Engine Harnesses LoRAX, Turbo LoRA, and Autoscaling GPUs to 3-4x Throughput and Cut Costs by Over 50% While Ensuring Reliability for High Volume Enterprise Workloads.
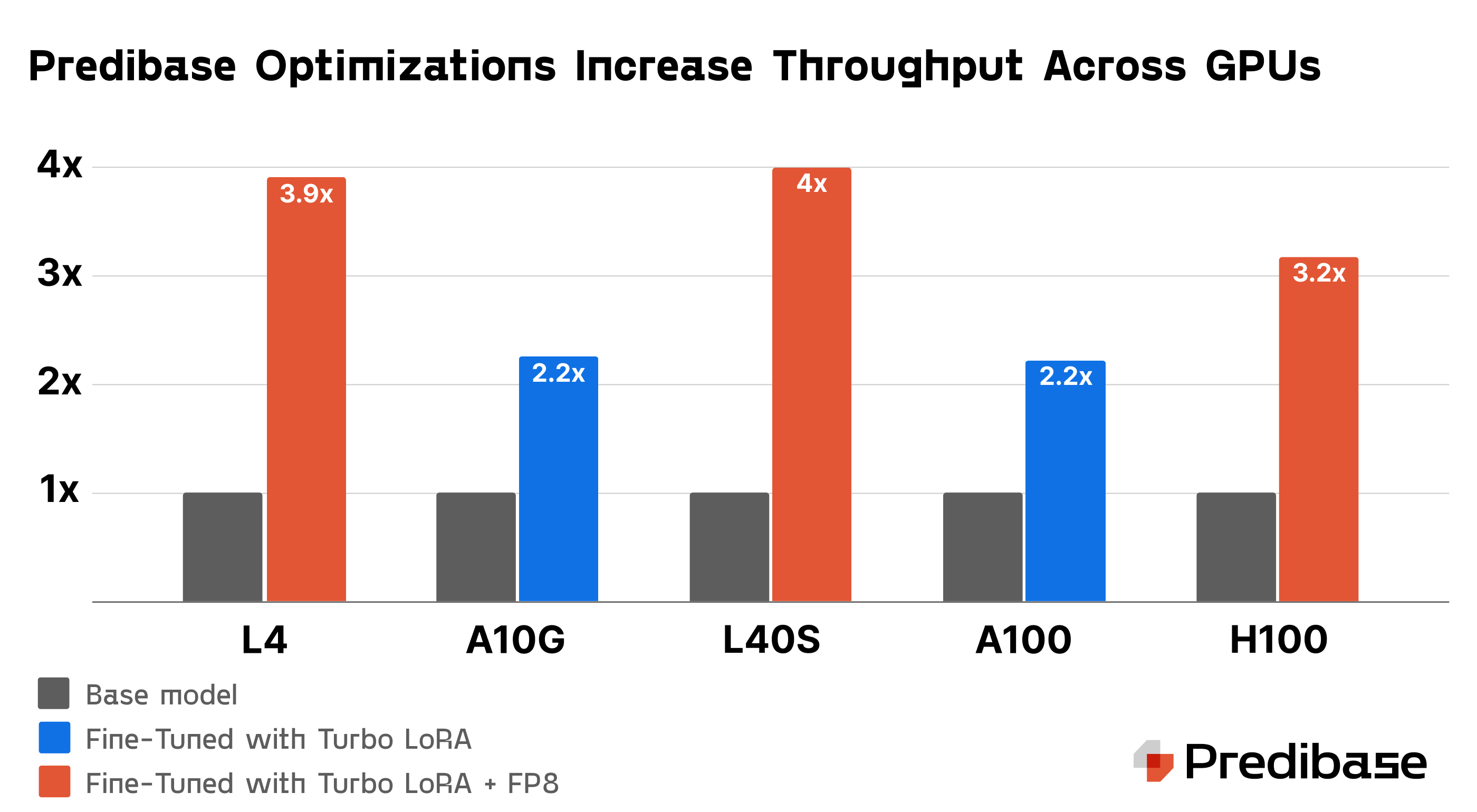
SAN FRANCISCO--(BUSINESS WIRE)--Today, Predibase unveiled the Predibase Inference Engine, its groundbreaking solution engineered to deploy fine-tuned small language models (SLMs) swiftly and efficiently across both private serverless (SaaS) and virtual private cloud (VPC) environments. The Predibase Inference Engine, powered by innovations such as LoRA eXchange (LoRAX – 2.1k stars on GitHub), Turbo LoRA, and seamless GPU autoscaling, serves fine-tuned SLMs at speeds 3-4 times faster than traditional methods and confidently handles enterprise workloads of hundreds of requests per second.
With customers including Checkr, Convirza, and Forethought, over 10,000 SLMs have been fine-tuned on Predibase. As the demand for fine-tuned models has skyrocketed, Predibase has evolved its platform to offer an end-to-end solution for both fine-tuning and serving specialized models. The new Predibase Inference Engine builds on this foundation, providing enterprises with unmatched speed, flexibility, and cost-efficiency when deploying fine-tuned SLMs.
“The success of open-source AI hinges on two crucial elements: the ability to fine-tune small language models effectively and the capability to deploy them at scale in a reliable and performant manner without overwhelming teams with the complexity of orchestrating infrastructure,” said Dev Rishi. “With the launch of the Predibase Inference Engine, we’re marrying our industry-leading fine-tuning capabilities with an enterprise-ready deployment solution. This combination ensures that our customers can fully leverage the power of fine-tuned SLMs, deploying them efficiently and effectively at scale, without the technical overhead intrinsic with building serving infra in-house.”
Leading Performance with LoRAX, Turbo LoRA, and FP8
At the core of the Predibase Inference Engine are Turbo LoRA and LoRAX, which together dramatically enhance the speed and efficiency of model serving. Coupled with FP8 quantization–which reduces the memory footprint for serving SLMs by nearly 50%–Turbo LoRA can increase fine-tuned model throughput by 3-4x compared to traditional serving methods, allowing teams to manage higher traffic volumes smoothly and swiftly while improving GPU cost efficiency.
LoRAX expands these capabilities by facilitating the serving of multiple fine-tuned models from a single GPU. This innovation significantly cuts down on the need for separate GPU instances for each model, streamlining operations and slashing infrastructure costs.
"At Convirza, our workload can be extremely variable, with spikes that require scaling up to double-digit A100 GPUs to maintain performance. The Predibase Inference Engine and LoRAX allow us to efficiently serve 60 adapters while consistently achieving an average response time of under two seconds," said Giuseppe Romagnuolo, VP of AI at Convirza. "Predibase provides the reliability we need for these high-volume workloads. The thought of building and maintaining this infrastructure on our own is daunting—thankfully, with Predibase, we don’t have to."
“Our customers are seeing substantial cost savings and speed improvements with Turbo LoRA,” said Rishi. “By optimizing inference times and reducing GPU hours, we’ve made it easier for organizations to scale their AI initiatives.”
Enterprise-Ready for Production AI Workloads
The Predibase Inference Engine is purpose-built for enterprises deploying AI in production environments, with features designed for scalability, reliability, and control:
- Deploy in Your Private Cloud: Deploy Predibase within your virtual private cloud so you can use your existing cloud spend commitments while benefiting from the power and performance of our software.
- Guaranteed GPU Capacity: Enterprise customers can reserve GPU resources from Predibase’s fleet of A100 and H100 GPUs, ensuring that mission-critical applications always have sufficient burst capacity to meet service-level agreements (SLAs).
- Cold Start Optimization: Rapidly ramp up additional GPUs to handle burst capacity, minimizing any cold start delays during traffic spikes.
- Multi-Region High Availability: Deploy mission-critical workloads across multiple regions to protect from outages. If one region experiences a disruption, our GPU autoscaling will bring additional capacity online to maintain throughput SLAs.
- Intuitive UI: Manage all aspects of fine-tuning and serving SLM through an easy-to-use UI and monitor your deployments with powerful performance dashboards.
The Predibase Inference Engine is an ideal solution for enterprises needing robust, scalable infrastructure to serve fine-tuned models reliably.
“Our customers trust us with massive, mission-critical workloads of hundreds of requests per second, and we take that responsibility seriously,” said Rishi. “They rely on Predibase because they know we provide the infrastructure and scale they need without having to build and maintain it themselves. We’re the go-to choice for enterprises looking to scale their AI operations efficiently and securely.”
Ready to Scale Your AI?
Predibase’s next-gen inference stack is available now for deployment in the Predibase cloud or your own VPC. To learn more about how Predibase can help you scale your fine-tuned models and optimize AI workloads, visit Predibase.com or request a demo today.
About Predibase
Deliver GPT-4 performance at a fraction of the cost with small models that you own!
Predibase is the fastest and most efficient way to customize small models for your use case and your data. As the developer platform for productionizing open-source AI, Predibase makes it easy to fine-tune and serve any model on cost-effective serverless infra that scales for the most demanding workloads. Predibase is trusted by organizations ranging from Fortune 500 enterprises through innovative startups like Convirza, Checkr, Nubank, Upstage, Sekure Payments, and Everstream Analytics. Most importantly, Predibase is built on open-source foundations and can be deployed in your private cloud so all of your data and models stay in your control. www.predibase.com.
Contacts
Kevin Pedraja,
Voxus PR
kpedraja@voxuspr.com



