

Cerebras Launches CePO, Enabling Realtime Reasoning Capabilities for Llama AI Models
Cerebras Launches CePO, Enabling Realtime Reasoning Capabilities for Llama AI Models
Cerebras Planning and Optimization (CePO) enables Llama 3.3 70B to outperform flagship Llama 3.1 405B model and leading closed source models
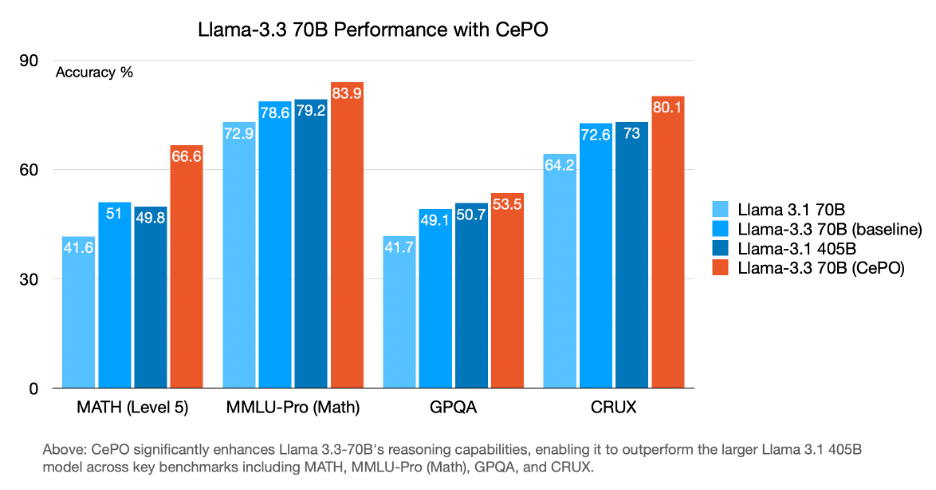
SUNNYVALE, Calif. & VANCOUVER, British Columbia--(BUSINESS WIRE)--Today at NeurIPS 2024, Cerebras Systems, the pioneer in accelerating generative AI, announced CePO (Cerebras Planning and Optimization), a powerful framework that dramatically enhances the reasoning capabilities of Meta's Llama family of models. Through sophisticated test-time computation techniques, CePO enables Llama 3.3-70B to outperform Llama 3.1 405B across challenging benchmarks while maintaining interactive speeds of 100 tokens per second – a first among test-time reasoning models.
The framework represents a significant breakthrough in making advanced reasoning capabilities accessible to the open-source AI community. While models like OpenAI o1 and Alibaba QwQ have demonstrated the power of additional computation at inference time, CePO brings these capabilities to Llama – the world's most popular open-source LLM family.
"CePO represents a significant advancement in LLM reasoning capabilities," said Ganesh Venkatesh, Head of Applied ML at Cerebras Systems. "By combining step-by-step reasoning with comparative analysis and structured outputs, we've enabled Llama 3.3-70B to surpass the performance of Llama 3.1-405B across multiple challenging benchmarks. Our results on MMLU-Pro (Math), GPQA, and CRUX demonstrate that sophisticated reasoning techniques can dramatically enhance model performance without requiring larger parameter counts."
CePO's effectiveness is demonstrated through its performance on challenging reasoning tasks that typically trip up even the most advanced AI models. In direct comparisons with GPT-4 Turbo and Claude 3.5 Sonnet, Llama 3.3-70B with CePO achieved comparable performance in CRUZ, LiveCodeBench, and GPQA benchmarks, while significantly outperforming in MATH evaluations. The framework has also shown remarkable success in classic reasoning challenges like the Strawberry Test and modified Russian Roulette problem, demonstrating true reasoning capabilities rather than mere pattern matching.
The CePO reasoning framework achieves these improvements through an innovative four-stage pipeline:
- Step-by-step planning for complex problem decomposition
- Multiple execution paths to ensure solution robustness
- Cross-execution analysis to identify and correct inconsistencies
- Structured confidence scoring within a Best-of-N framework
CePO uses a combination of reasoning techniques, generates multiple plans and checks its own work, consuming 10-20x more output tokens compared to one-shot approaches. However, thanks to Cerebras' hardware optimization, it still achieves speeds of 100 tokens per second – comparable to best-in-class chat applications like GPT-4 Turbo and Claude 3.5 Sonnet.
"CePO's ability to enhance reasoning capabilities while maintaining interactive speeds opens new possibilities for AI applications," said Andrew Feldman, CEO and co-founder of Cerebras Systems. "By bringing these capabilities to the Llama family of models, we're democratizing access to sophisticated reasoning techniques previously limited to closed commercial systems. This advancement will enable developers to build more sophisticated AI applications that require complex, multi-step reasoning in real-time scenarios."
To accelerate innovation in AI reasoning capabilities, Cerebras will open source the CePO framework, enabling researchers and developers worldwide to build upon and enhance these breakthrough techniques. The company's roadmap includes developing advanced prompting frameworks that leverage comparative reasoning, creating synthetic datasets optimized for inference-time computation, and building enhanced verification mechanisms for complex reasoning chains. For more information about CePO, read our technical blog post at cerebras.ai/blog/cepo.
About Cerebras Systems
Cerebras Systems is a team of pioneering computer architects, computer scientists, deep learning researchers, and engineers of all types. We have come together to accelerate generative AI by building from the ground up a new class of AI supercomputer. Our flagship product, the CS-3 system, is powered by the world's largest and fastest commercially available AI processor, our Wafer-Scale Engine-3. CS-3s are quickly and easily clustered together to make the largest AI supercomputers in the world, and make placing models on the supercomputers dead simple by avoiding the complexity of distributed computing. Cerebras Inference delivers breakthrough inference speeds, empowering customers to create cutting-edge AI applications. Leading corporations, research institutions, and governments use Cerebras solutions for the development of pathbreaking proprietary models, and to train open-source models with millions of downloads. Cerebras solutions are available through the Cerebras Cloud and on premise. For further information, visit cerebras.ai or follow us on LinkedIn or X.
Contacts
Media Contact
PR@zmcommunications.com