

TensorOpera Unveils Fox-1: Pioneering Small Language Model (SLM) for Cloud and Edge
TensorOpera Unveils Fox-1: Pioneering Small Language Model (SLM) for Cloud and Edge
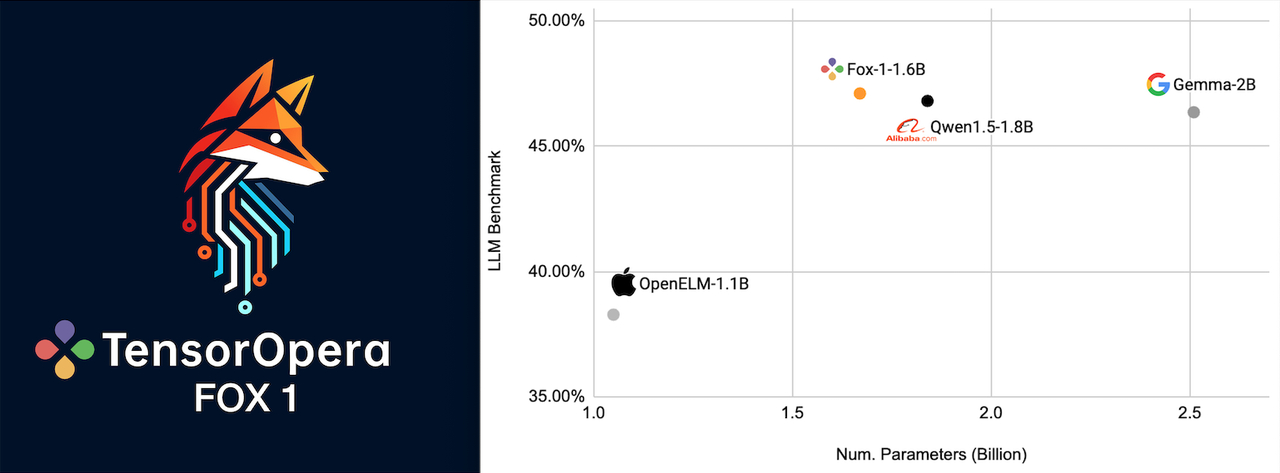
PALO ALTO, Calif.--(BUSINESS WIRE)--TensorOpera, the company providing `Your Generative AI Platform at Scale’, is excited to announce the launch of TensorOpera Fox-1. This 1.6-billion parameter small language model (SLM) is designed to advance scalability and ownership in the generative AI landscape. Fox-1 stands out by delivering top-tier performance, surpassing comparable SLMs developed by industry giants such as Apple, Google, and Alibaba. The combination of exceptional performance and cost-efficiency makes Fox-1 an ideal choice for developers and enterprises seeking to build their own generative AI models and applications, and deploy them across diverse infrastructures, all without the need for substantial resources.
Small language models with fewer than 2 billion parameters like Fox-1 are transforming the AI landscape by delivering powerful capabilities with much reduced computational and data requirements suitable for deployment on mobile and edge devices. This shift is crucial as it facilitates the deployment of AI applications across various platforms, from mobile devices to servers, all while maintaining exceptional performance.
“The launch of Fox-1 and its integration into TensorOpera’s AI platform is a major step towards our vision of providing an integrated edge-cloud platform for Generative AI,” remarks Salman Avestimehr, Co-Founder and CEO of TensorOpera and Dean’s Professor of ECE and CS at the University of Southern California. “This would enable seamless training, creation, and deployment of generative AI applications across a wide range of platforms and devices, ranging from powerful GPUs in cloud settings to edge devices like smartphones and AI-equipped PCs, enhancing efficiency, privacy, and personalization. This development highlights our commitment to delivering ‘Your Generative AI Platform at Scale’, which promotes ownership and scalability across both cloud and edge computing environments.”
Fox-1 was trained from scratch with a 3-stage data curriculum on 3 trillion tokens of text and code data in 8K sequence length. With a decoder-only transformer structure, 16 attention heads, and grouped query attention, Fox-1 is notably deeper and more capable than its peers (78% deeper than Google’s Gemma-2B, 33% deeper than Alibaba’s Qwen1.5-1.8B, and 15% deeper than Apple’s OpenELM-1.1B). In various benchmarks, such as MMLU, ARC Challenge, TruthfulQA, and GSM8k, Fox-1 performs better or on par with other SLMs in its class including Gemma-2B, Qwen1.5-1.8B, and OpenELM-1.1B.
“SLMs can effectively incorporate data in special domains in the pre-training phase, which leads to optimized expert models that can be trained and deployed in a decentralized fashion”, said Tong Zhang, Chief AI Scientist at TensorOpera and Professor of CS at UIUC. “The integration of domain-specific SLMs into innovative architectures such as Mixture of Experts (MoE) and model federation systems further enhances their utility, enabling the construction of more powerful systems by integrating expert SLMs to handle complex tasks.”
In terms of operational efficiency, Fox-1 achieves an impressive throughput of over 200 tokens per second on the TensorOpera model serving platform, surpassing the performance of Gemma-2B and equaling that of Qwen1.5-1.8B in identical deployment environments. The high throughput of Fox-1 can largely be attributed to its architectural design, which incorporates Grouped Query Attention (GQA) for more efficient query processing. More specifically, by dividing query heads into groups that share a common key and value, Fox-1 significantly improves inference latency and enhances response times.
The integration of Fox-1 into both TensorOpera AI Platform and TensorOpera FedML Platform further enhances its versatility, enabling its deployment and training across both cloud and edge computing environments. It empowers AI developers to train and build their models and applications on the cloud utilizing the comprehensive capabilities of the TensorOpera AI Platform, and then deploy, monitor, and personalize these solutions directly onto smartphones and AI-enabled PCs via the TensorOpera FedML platform. This approach offers cost efficiency, enhanced privacy, and personalized user experiences, all within a unified ecosystem that facilitates seamless collaboration between cloud and edge environments.
Fox-1 is released under the Apache 2.0 license through the TensorOpera AI Platform and Hugging Face, granting the community freedom for both production and research uses.
To learn more and get started on using Fox-1, dig into TensorOpera’s blogpost.
About TensorOpera, Inc.
TensorOpera, Inc. (formerly FedML, Inc.) is an innovative AI company based in Silicon Valley, specifically Palo Alto, California. TensorOpera specializes in developing scalable and secure AI platforms, offering two flagship products tailored for enterprises and developers. The TensorOpera® AI Platform, available at TensorOpera.ai, is a comprehensive generative AI platform for model deployment and serving, model training and fine-tuning, AI agent creation, and more. It supports launching training and inference jobs on a serverless/decentralized GPU cloud, experimental tracking for distributed training, and enhanced security and privacy measures. The TensorOpera® FedML Platform, accessible at FedML.ai, leads in federated learning and analytics with zero-code implementation. It includes a lightweight, cross-platform Edge AI SDK suitable for edge GPUs, smartphones, and IoT devices. Additionally, it offers a user-friendly MLOps platform to streamline decentralized machine learning and deployment in real-world applications. Founded in February 2022, TensorOpera has quickly grown to support a large number of enterprises and developers worldwide.
Contacts



