

Introducing Molmo: A Family of State-of-the-Art Open Multimodal Models
Introducing Molmo: A Family of State-of-the-Art Open Multimodal Models
Molmo goes beyond today’s most advanced multi-modal models by creating open models that can now point and act in the visual world
SEATTLE--(BUSINESS WIRE)--Today, the Allen Institute for AI (Ai2) announced the launch of Molmo, a family of state-of-the-art multimodal models. This family includes our best Molmo model, closing the gap between close and open models, the most open and powerful multimodal model today, and the most efficient model. Currently, most advanced multimodal models can perceive the world and communicate with us, Molmo goes beyond that to enable one to act in their worlds, unlocking a whole new generation of capabilities, everything from sophisticated web agents to robotics.
Key capabilities of Molmo include:
- Exceptional Image Understanding: Molmo can accurately understand a wide range of visual data, from everyday objects and signs to complex charts, messy whiteboards, clocks, and menus.
- Actionable Insights: To bridge the gap between perception and action, Molmo models can point to what they perceive, empowering a wide range of capabilities that require spatial knowledge. Molmo can effortlessly point to UI elements on the screen, enabling developers to build web agents or robots that can navigate complex interactions both on screen and within the real-world.
Molmo is accessible to everyone:
- Open: Molmo’s language and vision training data, fine tuning data, model weights, source code will all be open and available to the community.
- Efficient: The Molmo training recipe and models are incredibly data efficient, requiring far less compute than before, making it accessible to the entire community.
- Runs on device: The Molmo-1B model is tiny, fast and performant, small enough to fit on most devices.
Closing the gap between open and closed AI models
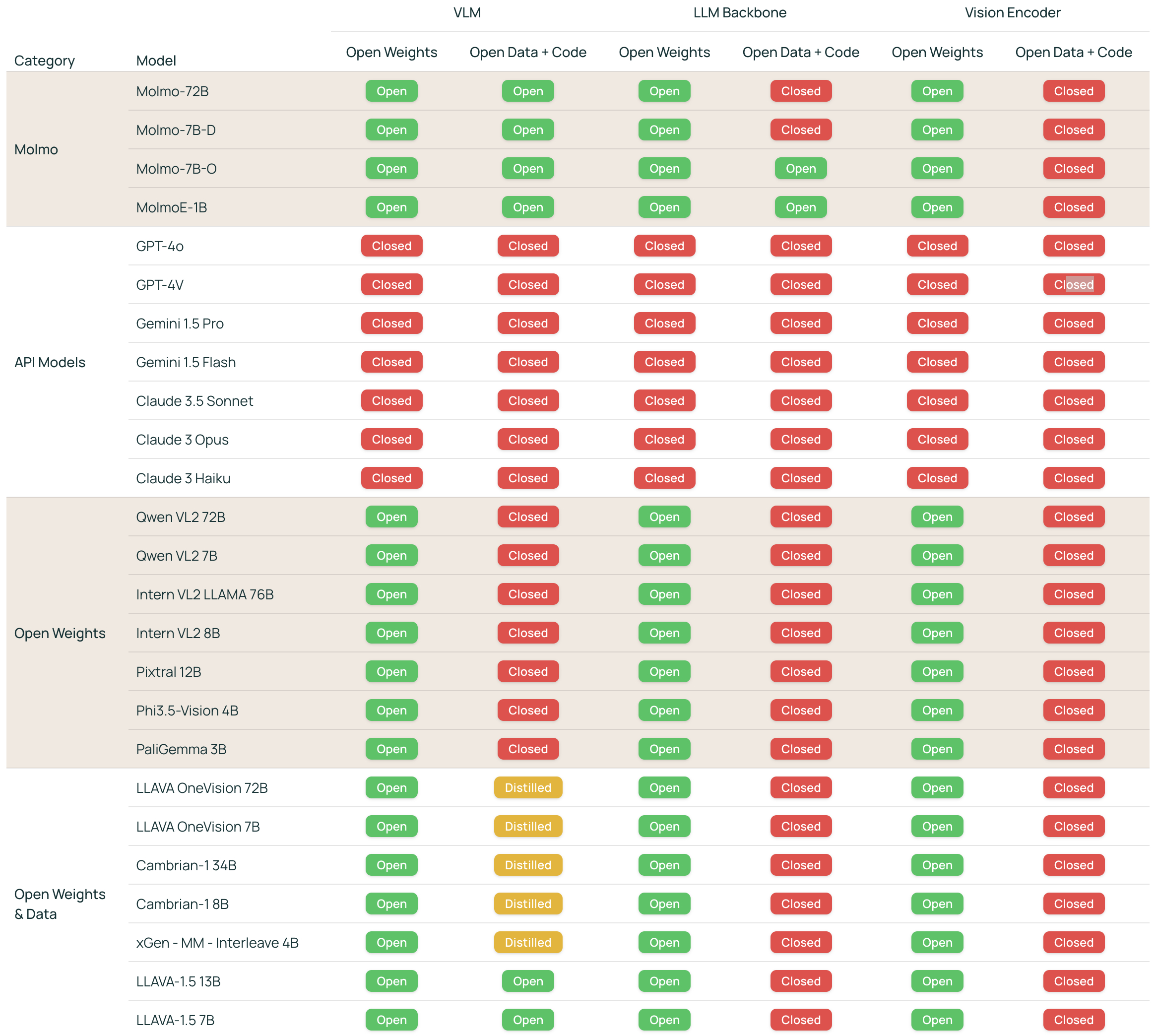
The accuracy and capability of Molmo models shows the gap between open and proprietary models is closing. The best in class 72B model within the Molmo family not only outperforms others in the class of open weight and data models, but also compares favorably against proprietary systems like GPT-4V, Claude 3.5 and Gemini 1.5.
Molmo was designed and built in the open and Ai2 will be releasing all model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available starting today. By sharing all data and code Ai2 continues to set the open standards for AI, providing open access to enable continued research and innovation in the AI community.
Smaller models are becoming as powerful as big
The Molmo family demonstrates that even smaller models (7B parameters) can perform as well as proprietary, more expensive alternatives. This approach lowers barriers to development and provides a robust foundation for the AI community to build innovative applications around Molmo’s unique capabilities. The Molmo family includes our most efficient model built with OLMo-E that has only 1 billion active parameters, making it suitable to be deployed to devices.
Molmo’s efficient and open multimodal data
Molmo leapfrogs model performance through efficient and creative use of data. Unlike recent multimodal LLMs that rely on massive webscale language-vision data, Molmo is trained using a meticulously curated set of slightly under 1 million images, demonstrating that a focused, efficient approach can yield superior results without the need for extensive computational resources.
The key innovation is a novel, highly-detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture including innovative 2D pointing data that enhances tasks like counting and creates a foundation for future directions in which VLMs enable agents to act by pointing in their environments. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and most critically the quality of our newly collected datasets, all of which will be fully released.
“Molmo is an incredible AI model with exceptional visual understanding, which pushes the frontier of AI development by introducing a paradigm for AI to interact with the world through pointing. The model's performance is driven by a remarkably high quality curated dataset to teach AI to understand images through text. The training is so much faster, cheaper, and simpler than what's done today, such that the open release of how it is built will empower the entire AI community, from startups to academic labs, to work at the frontier of AI development,” said Matt Deitke, Researcher at the Allen Institute for AI.
“Multimodal AI models are typically trained on billions of images. We have instead focussed on using extremely high quality data but at a scale that is 1000 times smaller. This has produced models that are as powerful as the best proprietary systems, but with fewer hallucinations and much faster to train, making our model far more accessible to the community,” said Ani Kembhavi, Senior Director of Research at the Allen Institute for AI.
Building Molmo for a Better AI Future
Molmo represents a critical step forward for the AI community. The combined power of capabilities that are actionable in the real-world operating at state-of-the-art performance in a model that is free, openly available, and efficient to deploy opens the possibility for all researchers, developers, and consumers to have access to use, build, and advance safe and openly available AI in our visual world.
Learn more: https://molmo.allenai.org/blog
Try now: https://molmo.allenai.org/
Contacts
Sophie Lebrecht
sophiel@allenai.org