
")
")

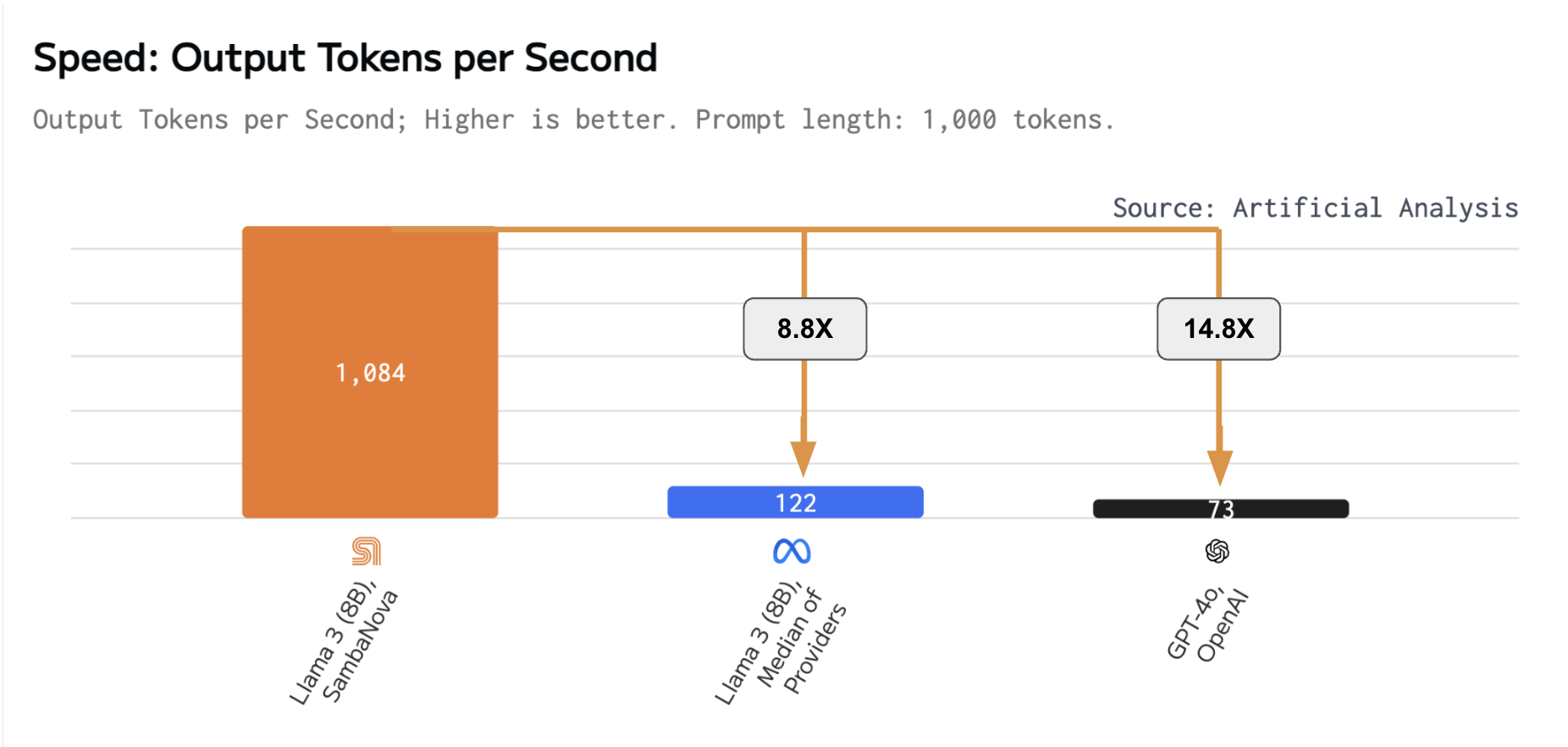
PALO ALTO, Calif.--(BUSINESS WIRE)--SambaNova Systems, the generative AI solutions company with the fastest models and most advanced chips, is the clear winner of the latest large language model (LLM) benchmark by Artificial Analysis. Topping their Leaderboad at over 1000 tokens per second (t/s), Samba-1 Turbo sets a new record for Llama 3 8B performance.
“Our mission is to give every enterprise a custom AI system that comes at a lower cost,” said Rodrigo Liang, CEO and founder of SambaNova. “Blazing inference speed that doesn’t compromise accuracy is what developers need to put the power of a personalized LLM into the hands of their organization to streamline workflows and innovate faster.”
Micah Hill-Smith, Co-Founder & CEO of Artificial Analysis stated: “SambaNova's Samba-1 Turbo has set a new record for large language model inference performance in recent benchmarking by Artificial Analysis.
Artificial Analysis has independently benchmarked Samba-1 Turbo performance on Meta’s Llama 3 Instruct (8B) at 1,084 output tokens per second, more than 8 times faster than the median output speed across providers we benchmark. Artificial Analysis has verified that Llama 3 Instruct (8B) on Samba-1 Turbo achieves quality scores in line with 16-bit precision.
New frontiers in language model inference speed unlock new ways of building AI applications. Emerging use-cases include agents taking multi-step actions while maintaining seamless conversation, real-time voice experiences and high-volume document interpretation.”
Unlike competitors, which run the same model on hundreds of chips, Samba-1 Turbo runs Llama 3 8B at 1000 tokens per second (t/s) on just 16 chips, and can concurrently host up to 1000 Llama3 checkpoints on a single 16-socket SN40L node. This is the fastest speed for serving Llama 3, while maintaining full precision, at a much lower cost than competitors. The nearest competitor requires hundreds of chips to run a single instance of each model due to memory capacity limitations, and GPUs offer lower total throughput and lower memory capacity. SambaNova can run hundreds of models on a single node while maintaining this record speed, providing a 10x lower total cost of ownership than competitors.
"Samba-1 Turbo’s speed shows the beauty of Dataflow, which streamlines data movement on SN40L chips, minimizing latency, and maximizing processing throughput. It’s superior to the GPU – the result is instant AI,” said Kunle Olukotun, co-founder of SambaNova Systems and renowned computer scientist at Stanford University.
Try Samba-1 Turbo today!
About SambaNova Systems
Customers turn to SambaNova to quickly deploy state-of-the-art AI capabilities to meet the demands of the AI-enabled world. Our purpose-built enterprise-scale AI platform is the technology backbone for the next generation of AI computing. We enable customers to unlock the valuable business insights trapped in their data. Our flagship offering, SambaNova Suite, overcomes the limitations of legacy technology to power the large complex foundation models that enable customers to discover new services and revenue streams, and boost operational efficiency.
Headquartered in Palo Alto, California, SambaNova Systems was founded in 2017 by industry luminaries, and hardware and software design experts from Sun/Oracle and Stanford University. Investors include SoftBank Vision Fund 2, funds and accounts managed by BlackRock, Intel Capital, GV, Walden International, Temasek, GIC, Redline Capital, Atlantic Bridge Ventures, Celesta, and several others. sambanova.ai – info@sambanova.ai – Linkedin – X
Footnote: Artificial Analysis offers independent analysis of AI language models and API providers. The company provides benchmarking and related information to support people & organizations in choosing the right model for their use-case and which provider to use for that model.
