
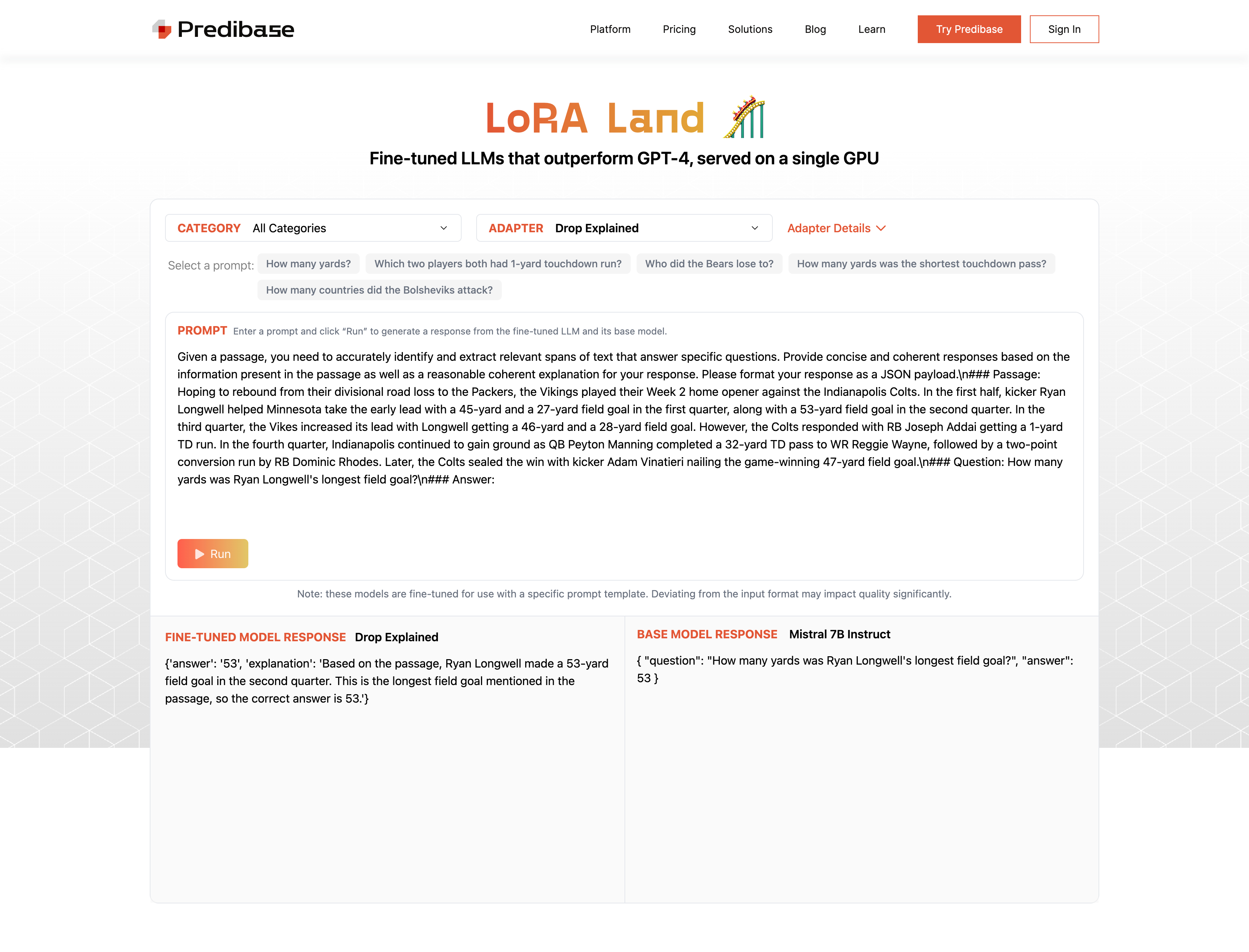



SAN FRANCISCO--(BUSINESS WIRE)--Predibase, the developer platform for fine-tuning LLMs, today introduced LoRA Land, a collection of 25 open-source fine-tuned models that rival or outperform GPT-4.0. Designed to serve use cases ranging from sentiment analysis to summarization, LoRA Land demonstrates the simplicity and cost effectiveness of training highly accurate, specialized LLMs with Predibase. LoRA Land is powered by the open-source LoRAX framework and Predibase’s Serverless Fine-tuned Endpoints, showcasing how teams can serve many fine-tuned LLMs cost-effectively on a single GPU. Visit LoRA Land to prompt any of these 25+ fine-tuned models in real-time, or get started fine-tuning and serving a collection of highly performant specialized models at a fraction of the cost with Predibase and LoRAX.
“Organizations are increasingly recognizing the benefits of having many smaller, fine tuned models for different use cases and customers,” said Dev Rishi, co-founder and CEO of Predibase. According to internal data, 65% of surveyed organizations plan on deploying two or more fine-tuned LLMs in the next 12 months, and 18% plan on deploying 6 or more.
The prohibitive cost of building GPT models from scratch or fine-tuning an entire model with billions or trillions of parameters is driving the adoption of smaller, specialized LLMs and efficient approaches like Parameter-Efficient Fine-Tuning (PEFT) and Low-Rank Adaptation. Predibase has incorporated these best practices into its fine-tuning platform and, to demonstrate the accessibility and affordability of adapter-based fine-tuning of open-source LLMs, has fine-tuned over 25 models for less than $8 each on average in terms of GPU costs.
Fine-tuned LLMs have historically also been very expensive to put into production and serve, requiring dedicated GPU resources for each fine-tuned model. For teams that plan on deploying multiple fine-tuned models to address a range of use cases, these GPU expenses can often be a bottleneck for innovation. LoRAX, the open-source platform for serving fine-tuned LLMs developed by Predibase, enables teams to deploy hundreds of fine-tuned LLMs for the cost of one from a single GPU.
“We help coaches, educators and even musicians connect and share knowledge with millions of WhatsApp users via human-like chatbots that incorporate text, image and voice,” said Andres Restrepo, CEO of innovative startup Enric.ai. “This requires using LLMs for many use cases like translation, intent classification, and generation. By switching from OpenAI to Predibase we’ve been able to fine-tune and serve many specialized open-source models in real-time, saving us over $1 million annually, while creating engaging experiences for our audiences. Best of all we own the models.”
By building LoRAX into the Predibase platform and serving many fine-tuned models from a single GPU, Predibase is able to offer customers Serverless Fine-tuned Endpoints, meaning users don’t need dedicated GPU resources for serving. This enables:
- Significant cost savings: Only pay for what you use. No more paying for a dedicated GPU when you don’t need it.
- Scalable infrastructure: LoRAX enables Predibase’s serving infrastructure to scale with your AI initiatives. Whether you’re testing one fine-tuned model or deploying one hundred in production, our infra meets you where you are.
- Instant deployment and prompting: By not waiting for a cold GPU to spin up before prompting each fine-tuned adapter, you can test and iterate on your models much faster.
We built LoRA Land to provide a real world example of how LoRAX and Serverless Fine-tuned Endpoints make it much faster and far more resource efficient for organizations to fine-tune and serve 100s of their own LLMs. That’s a game changer for organizations that want to start deploying many different specialized LLMs to power their business.
To experience this, organizations can reproduce the fine-tuned models from LoRA Land using the provided configuration files or can use their own data to fine-tune models in the Free Trial or Developer Tier of the Predibase platform. Stay tuned for a deeper analysis of the benchmarks against GPT-4.
About Predibase
Predibase is the fastest and most efficient way for developers to build their own specialized LLMs in the cloud. As the developer platform for fine-tuning and serving LLMs, Predibase makes it easy for engineering teams to fine-tune and serve any open-source AI model on state-of-the-art serverless infrastructure. Predibase is trusted by organizations ranging from Fortune 500 enterprises through innovative startups like Sekure Payments, Whatfix, Papershift and World Wildlife Fund. Built by the team that created the internal AI platforms at Apple and Uber, Predibase is fast, efficient, and scalable for any size job. Most importantly, Predibase is built on open-source foundations and can be deployed in your cloud so all of your data and models stay in your control.
For more information or to get started with a free trial, visit http://www.predibase.com or follow @predibase.
